Assists businesses in taming their data and leveraging it to discover new opportunities, resulting in better business decisions, more successful operations, more profitability, and happier consumers. This means that converting big data into experiences offers up new possibilities. Exams and network administration of large volumes of data To help you extract knowledge from your data and fine-tune your products and services, provide advance responses. We make information available and secure. Plans are being made for a huge data examination. Assist organisations in building serious information-gathering, storage, measurement, and dissection systems based on the four-overlay technique.
Addepto is a high-end company. A well-organized examination system and a large volume of data Furthermore, our strong examination abilities, inside and outside space knowledge, information the executives abilities, and AI excellence have aided us in developing a successful history of collaborating with leading associations' Big data and Analytics activities in all areas and areas, including Financial. Businesses have been ignoring Big Data for a long time. Then they have to deal with massive haystacks and data mazes. In the flash of an eye, the world shifted from Exam to Yuta, and actual competitive edge was exposed beneath these mountains and mazes. Big Data, on the other hand, was and continues to be a fickle genie. It's meaningless to collect reams and reams of data that are inactive and smelly unless someone can extract the insights contained therein quickly, efficiently, and deeply. To get the most out of Big Data, the concerns of cold, warm, and hot data must be addressed. While your competitors are busy stacking haystacks, we help you get to the needles faster.
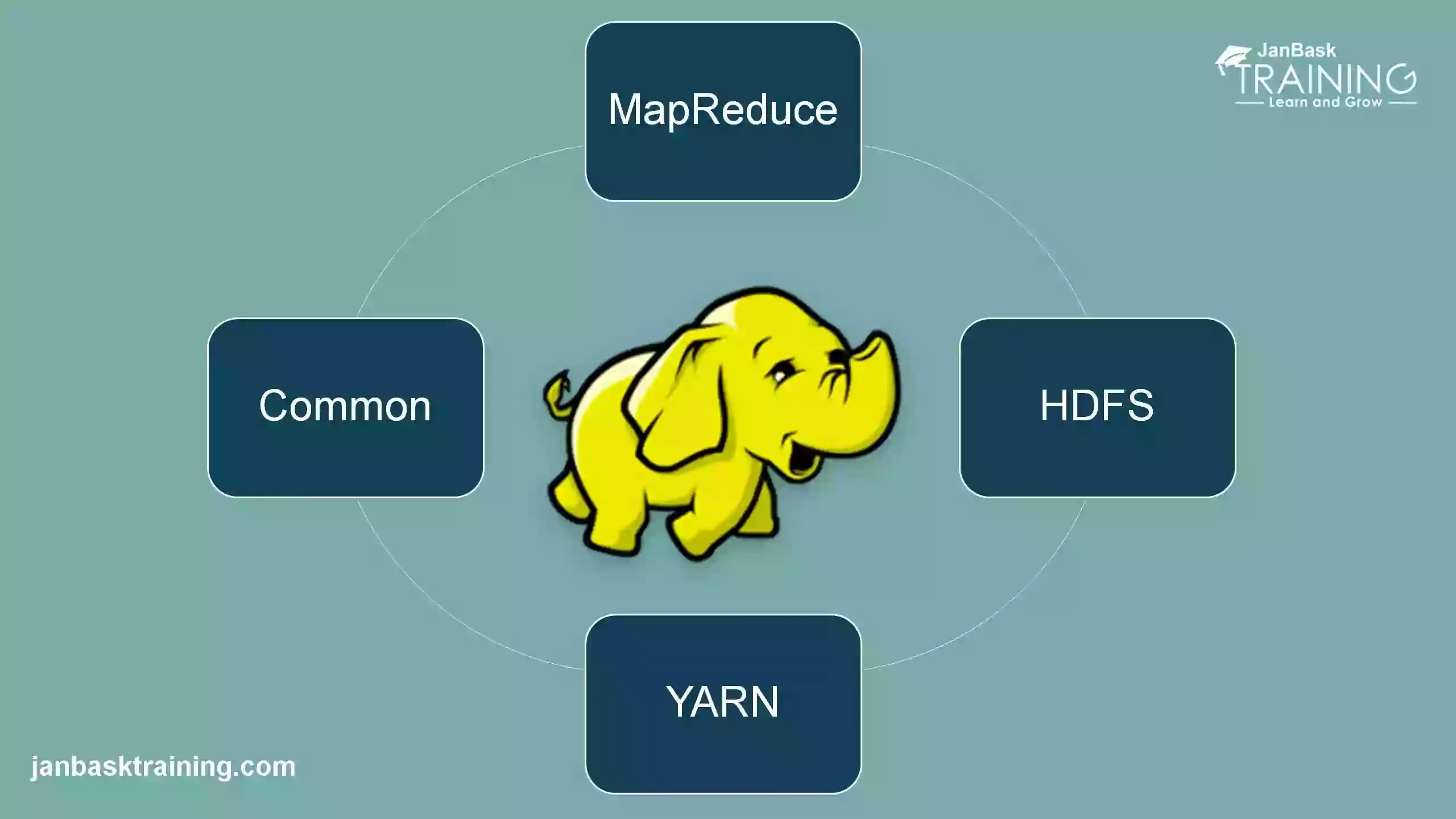
Hadoop is an open source framework for storing and analysing massive volumes of data that is built on Java. The information is kept on a cluster of low-cost commodity servers. The distributed file system enables concurrent processing and fault tolerance.
Hadoop is an open source framework for storing and analysing massive volumes of data that is built on Java. The information is kept on a cluster of low-cost commodity servers. The distributed file system enables concurrent processing and fault tolerance. Hadoop, which was designed by Doug Cutting and Michael J, use the Map Reduce programming paradigm to more swiftly store and retrieve data from its nodes. The framework is managed by the Apache Software Foundation and distributed under the Apache License 2.0. While the processing power of application servers has skyrocketed in recent years, databases have lagged behind due to their limited capacity and speed. The Map Reduce programming model is used by Had loop, which was invented by Doug Cutting and Michael J, to store and retrieve data from its nodes more fast.
Furthermore, the ability to collect large amounts of data and the insights gained from crunching that data leads to better real-world business decisions, such as being able to focus on the right customer segment, weeding out or fixing inefficient processes, optimising floor operations, providing relevant search results, performing predictive analytics, and so on. Hadoop is a platform that consists of a number of interconnected components that enable distributed data storage and processing. These components make up the Hadoop ecosystem. Some of these are core components that make up the framework's foundation, while others are add-ons that enhance Hadoop's functionality. From a commercial standpoint, there are both direct and indirect advantages. Open-source technology are used on low-cost servers, which are frequently in the cloud, to save money for businesses (though occasionally on-premises).
Addepto IT is a web design and development firm based in India that specialises in web and mobile application development, as well as e-commerce and CMS development and local SEO. We deliver fashionable and cost-effective websites for organisations looking for cost-effective Website Designing and quick Web Development solutions. Our web development team works tirelessly to provide the best technical solution for your project. IT Spark Technology is a web and app development firm that also provides SEO and SMO services to a number of office locations.
Every phase of web design and development at IT Spark Technology is defined by diligent professionals and web architects from different walks of life. Their main goal is to show to the rest of the world a professional and cost-effective web solution that meets all of the company's internal needs while also performing extraordinarily well with their web clients. Framework.
Apache Spark requires a pack chairman and a distributed accumulation system. Spark keeps an autonomous (neighbourhood Flash pack for bunching the board, where you can dispatch a pack manually or using the current group's dispatch substance. For testing purposes, these daemons can also be run on a single machine), YARN, Apache Notices, or Cabernets. Flash can talk to Hadoop Distributed File System (HDFS), Guide Document Framework (Guide FS), Cassandra, Open Stack Quick, Amazon S3, Kudu, Spark Record Framework, or a custom game plan. Spark also has a pseudo-passed on close by mode, which is commonly used for progress or testing where a set limit isn't required and the local archive system can be used with everything taken into account; in this case, Spark is run on a single machine with one specialist for each central processor position.
Many individuals use Kafka as an alternative to a log collection system. Log aggregation gathers workers' actual log documents and saves them in a central location for processing (maybe a record worker or HDFS). Kafka abstracts record nuances, allowing for a clearer view of log or event data as a flurry of messages. This explains why inactivity management is easier and why varied information sources and distributed information consumption are easier. Because each client site visit generates many movement signals, action following is frequently very high in volume.
Kafka delivers comparably high performance to log-driven systems like Scribe or Flume, as well as better grounded solidity due to replication and significantly decreased start-to-finish idleness. Stream Processing is a real-time data processing approach. Many Kafka clients collect data in multi-stage pipelines, in which raw data from Kafka topics is burned through, then accumulated, advanced, or changed into new themes for further usage or processing.
The initial application of Kafka was to re-engineer a client movement tracking pipeline as a series of continuous distribution buy-ins. This means that site activity (such as site visits, looks, and other consumer activities) is split into focus themes, with one point awarded to each type of action. Because each client site visit generates many movement signals, action following is frequently very high in volume. Kafka collects data in stages, with raw data from Kafka topics being burned through and then aggregated, advanced, or in any case changed into new themes for future use or processing.

Exemptions are addressed as soon as possible when degenerate data is detected early. Because the tables are compelled to coordinate with the outline after/during the data load, it has improved inquiry time execution. Hive, on the other hand, can stack data without doing a blueprint check, resulting in a smaller initial load but substantially slower query execution. Hive has an advantage when the composition isn't free at heap time and is instead produced dynamically thereafter. Exchanges are necessary in traditional data sets.
This strategy's name is Diagram on Compose. While Hive is examining the data, it does not validate it against the table pattern. When the data is viewed, it is subjected to timing checks. Hive, like every other RDBMS, preserves each of the four characteristics of exchanges (ACID): Atomicity, Consistency, Isolation, and Durability. Exchanges were introduced in Hive 0.13, although only at the parcel level. To help overall ACID characteristics, these capabilities have been fully implemented to the most recent version of Hive 0.14. With Hive 0.14 and later, INSERT, DELETE, and UPDATE are all supported at the column level. Hive's querying capabilities and processing power are very similar to those of traditional data stores.
While Hive is a SQL dialect, its architecture and features set it apart from other social information databases. The primary differences are that Hive is built on top of Map Reduce and must accept its limits. The initial application of Kafka was to re-engineer a client movement tracking pipeline as a series of continuous distribution buy-ins. This means that site activity (such as site visits, looks, and other consumer activities) is split into focus themes, with one point awarded to each type of action.






